Chapter 4 Data preprocessing¶
The methods we describe in this chapter are driven by financial applications. For an introduction to non-financial data processing, we recommend two references: chapter 3 from the general purpose ML book by Boehmke and Greenwell (2019) and the monograph on this dedicated subject by Kuhn and Johnson (2019).
4.1 Know your data¶
The first step, as in any quantitative study, is obviously to make sure the data is trustworthy, i.e., comes from a reliable provider (a minima). The landscape in financial data provision is vast to say the least: some providers are well established (e.g., Bloomberg, Thomson-Reuters, Datastream, CRSP, Morningstar), some are more recent (e.g., Capital IQ, Ravenpack) and some focus on alternative data niches (see https://alternativedata.org/data-providers/ for an exhaustive list). Unfortunately, and to the best of our knowledge, no study has been published that evaluates a large spectrum of these providers in terms of data reliability.
The second step is to have a look at summary statistics: ranges (minimum and maximum values), and averages and medians. Histograms or plots of time series carry of course more information but cannot be analyzed properly in high dimensions. They are nonetheless sometimes useful to track local patterns or errors for a given stock and/or a particular feature. Beyond first order moments, second order quantities (variances and covariances/correlations) also matter because they help spot colinearities. When two features are highly correlated, problems may arise in some models (e.g., simple regressions, see Section 15.1).
Often, the number of predictors is so large that it is unpractical to look at these simple metrics. A minimal verification is recommended. To further ease the analysis:
- focus on a subset of predictors, e.g., the ones linked to the most common factors (market-capitalization, price-to-book or book-to-market, momentum (past returns), profitability, asset growth, volatility);
- track outliers in the summary statistics (when the maximum/median or median/minimum ratios seem suspicious).
Below, in Figure 4.1, we show a box plot that illustrates the distribution of correlations between features and the one month ahead return. The correlations are computed on a date-by-date basis, over the whole cross-section of stocks. They are mostly located close to zero, but some dates seem to experience extreme shifts. The market capitalization has the median which is the most negative while volatility is the only predictor with positive median correlation (this particular example seems to refute the low risk anomaly).
import seaborn as sns
import matplotlib.pyplot as plt
cols=[] # cleaning the column list from previous use
cols= features_short+['R1M_Usd','date'] # Keep few features, label & dates
data_corr = data_ml[cols] # Creating the working dataset
data_corr = data_corr.groupby('date').corr()[['R1M_Usd']].reset_index() # Group for computing correlation
data_corr= data_corr.loc[data_corr[data_corr.level_1.str[-7:] != "R1M_Usd"].index] # removing correl=1 instances from label
data_corr.rename(columns={'level_1': "Factors"},inplace=True) # Renaming fro plotting later
plt.figure(figsize=(12,6)) # resizing the chart
sns.swarmplot(x="Factors", y="R1M_Usd", data=data_corr); # Plot from seaborn

FIGURE 4.1: Swarnplot of correlations with the 1M forward return (label).
More importantly, when seeking to work with supervised learning (as we will do most of the time), the link of some features with the dependent variable can be further characterized by the smoothed conditional average because it shows how the features impact the label. The use of the conditional average has a deep theoretical grounding. Suppose there is only one feature
$X$ and that we seek a model $Y=f(X)+\text{error}$, where variables are real-valued. The function $f$ that minimizes the average squared error $\mathbb{E}[(Y-f(X))^2]$ is the so-called regression function (see Section 2.4 in Hastie, Tibshirani, and Friedman (2009)):
In Figure 4.2, we plot two illustrations of this function when the dependent variable ($Y$) is the one month ahead return. The first one pertains to the average market capitalization over the past year and the second to the volatility over the past year as well. Both predictors have been uniformized (see Section 4.4.2 below) so that their values are uniformly distributed in the cross-section of assets for any given time period. Thus, the range of features is $[0,1]$ and is shown on the $x$-axis of the plot. The colored corridors around the lines show 95% level confidence interval for the computation of the mean. Essentially, it is narrow when both (i) many data points are available and (ii) these points are not too dispersed.
from matplotlib import pyplot as plt
import seaborn as sns
unpivoted_data_ml = pd.melt(data_ml[['R1M_Usd','Mkt_Cap_12M_Usd','Vol1Y_Usd']], id_vars='R1M_Usd') # selecting and putting in vector
plt.figure(figsize=(13,8))
sns.lineplot(data = unpivoted_data_ml, y='R1M_Usd', x='value', hue='variable'); # Plot from seaborn

FIGURE 4.2: Conditional expectations: average returns as smooth functions of features.
The two variables have a close to monotonic impact on future returns. Returns, on average, decrease with market capitalization (thereby corroborating the so-called size effect). The reverse pattern is less pronounced for volatility: the curve is rather flat for the first half of volatility scores and progressively increases, especially over the last quintile of volatility values (thereby contradicting the low-volatility anomaly).
One important empirical property of features is autocorrelation (or absence thereof). A high level of autocorrelation for one predictor makes it plausible to use simple imputation techniques when some data points are missing. But autocorrelation is also important when moving towards prediction tasks and we discuss this issue shortly below in Section 4.6. In Figure 4.3, we build the histogram of autocorrelations, computed stock-by-stock and feature-by-feature.
cols=[] # cleaning the column list from previous use
cols = ['stock_id'] + list(data_ml.iloc[:,3:95].columns) # Keep all features and stockid
# below the nested line of code for sorting according the pair stockid/variable and then compute the acf
data_hist_acf=pd.melt(data_ml[cols], id_vars='stock_id').groupby(['stock_id','variable']).apply(lambda x: x['value'].autocorr(lag=1))
plt.figure(figsize=(13,8))
data_hist_acf.hist(bins=50,range=[-0.1,1]); # Plot from pandas

FIGURE 4.3: Histogram of sample feature autocorrelations.
4.2 Missing data¶
Similarly to any empirical discipline, portfolio management is bound to face missing data issues. The topic is well known and several books detail solutions to this problem (e.g., Allison (2001), Enders (2010), Little and Rubin (2014) and Van Buuren (2018)). While researchers continuously propose new methods to cope with absent points (Honaker and King (2010) or Che et al. (2018) to cite but a few), we believe that a simple, heuristic treatment is usually sufficient as long as some basic cautious safeguards are enforced.
First of all, there are mainly two ways to deal with missing data: removal and imputation. Removal is agnostic but costly, especially if one whole instance is eliminated because of only one missing feature value. Imputation is often preferred but relies on some underlying and potentially erroneous assumption.
A simplified classification of imputation is the following:
- A basic imputation choice is the median (or mean) of the feature for the stock over the past available values. If there is a trend in the time series, this will nonetheless alter the trend. Relatedly, this method can be forward-looking, unless the training and testing sets are treated separately.
- In time series contexts with views towards backtesting, the most simple imputation comes from previous values: if $x_t$ is missing, replace it with $x_{t-1}$. This makes sense most of the time because past values are all that is available and are by definition backward-looking. However, in some particular cases, this may be a very bad choice (see words of caution below).
- Medians and means can also be computed over the cross-section of assets. This roughly implies that the missing feature value will be relocated in the bulk of observed values. When many values are missing, this creates an atom in the distribution of the feature and alters the original distribution. One advantage is that this imputation is not forward-looking.
- Many techniques rely on some modelling assumptions for the data generating process. We refer to nonparametric approaches (Stekhoven and Bühlmann (2011) and Shah et al. (2014), which rely on random forests, see Chapter 6), Bayesian imputation (Schafer (1999)), maximum likelihood approaches (Enders (2001), Enders (2010)), interpolation or extrapolation and nearest neighbor algorithms (Garcı́a-Laencina et al. (2009)). More generally, the four books cited at the begining of the subsection detail many such imputation processes. Advanced techniques are much more demanding computationally.
A few words of caution:
- Interpolation should be avoided at all cost. Accounting values or ratios that are released every quarter must never be linearly interpolated for the simple reason that this is forward-looking. If numbers are disclosed in January and April, then interpolating February and March requires the knowledge of the April figure, which, in live trading will not be known. Resorting to past values is a better way to go.
- Nevertheless, there are some feature types for which imputation from past values should be avoided. First of all, returns should not be replicated. By default, a superior choice is to set missing return indicators to zero (which is often close to the average or the median). A good indicator that can help the decision is the persistence of the feature through time. If it is highly autocorrelated (and the time series plot create a smooth curve, like for market capitalization), then imputation from the past can make sense. If not, then it should be avoided.
- There are some cases that can require more attention. Let us consider the following fictitious sample of dividend yield:
| Date | Original yield | Replacement value |
|---|---|---|
| 2015-02 | NA | preceding (if it exists) |
| 2015-03 | 0.02 | untouched (none) |
| 2015-04 | NA | 0.02 (previous) |
| 2015-05 | NA | 0.02 (previous) |
| 2015-06 | NA | <=Problem! |
TABLE 4.1: Challenges with chronological imputation.
In this case, the yield is released quarterly, in March, June, September, etc. But in June, the value is missing. The problem is that we cannot know if it is missing because of a genuine data glitch, or because the firm simply did not pay any dividends in June. Thus, imputation from past value may be erroneous here. There is no perfect solution but a decision must nevertheless be taken. For dividend data, three options are:
- Keep the previous value. In R, the function na.locf() from the zoo package is incredibly efficient for this task.
- Extrapolate from previous observations (this is very different from interpolation): for instance, evaluate a trend on past data and pursue that trend.
- Set the value to zero. This is tempting but may be sub-optimal due to dividend smoothing practices from executives (see for instance Leary and Michaely (2011) and Chen, Da, and Priestley (2012) for details on the subject). For persistent time series, the first two options are probably better.
Tests can be performed to evaluate the relative performance of each option. It is also important to remember these design choices. There are so many of them that they are easy to forget. Keeping track of them is obviously compulsory. In the ML pipeline, the scripts pertaining to data preparation are often key because they do not serve only once!
4.3 Outlier detection¶
The topic of outlier detection is also well documented and has its own surveys (Hodge and Austin (2004), Chandola, Banerjee, and Kumar (2009) and Gupta et al. (2014)) and a few dedicated books (Aggarwal (2013) and Rousseeuw and Leroy (2005), though the latter is very focused on regression analysis).
Again, incredibly sophisticated methods may require a lot of efforts for possibly limited gain. Simple heuristic methods, as long as they are documented in the process, may suffice. They often rely on ‘hard’ thresholds:
- for one given feature (possibly filtered in time), any point outside the interval $[\mu-m\sigma, \mu+m\sigma]$ can be deemed an outlier. Here $μ$ is the mean of the sample and $σ$ the standard deviation. The multiple value $m$ usually belongs to the set $\{3, 5, 10\}$, which is of course arbitrary.
- likewise, if the largest value is above $m$ times the second-to-largest, then it can also be classified as an outlier (the same reasoning applied for the other side of the tail).
- finally, for a given small threshold $q$, any value outside the $[q,1-q]$ quantile range can be considered outliers.
This latter idea was popularized by winsorization. Winsorizing amounts to setting to $x^{(q)}$ all values below x(q) and to x(1−q) all values above x(1−q) . The winsorized variable ~x is:
$\tilde{x}_i=\left\{\begin{array}{ll} x_i & \text{ if } x_i \in [x^{(q)},x^{(1-q)}] \quad \text{ (unchanged)}\\ x^{(q)} & \text{ if } x_i < x^{(q)} \\ x^{(1-q)} & \text{ if } x_i > x^{(1-q)} \end{array} \right. .$
The range for $q$ is usually $(0.5\%, 5\%)$ with 1% and 2% being the most often used.
The winsorization stage must be performed on a feature-by-feature and a date-by-date basis. However, keeping a time series perspective is also useful. For instance, a $800B market capitalization may seems out of range, except when looking at the history of Apple’s capitalization.
We conclude this subsection by recalling that true outliers (i.e., extreme points that are not due to data extraction errors) are valuable because they are likely to carry important information.
4.4 feature engineering¶
Feature engineering is a very important step of the portfolio construction process. Computer scientists often refer to the saying “garbage in, garbage out”. It is thus paramount to prevent the ML engine of the allocation to be trained on ill-designed variables. We invite the interested reader to have a look at the recent work of Kuhn and Johnson (2019) on this topic. The (shorter) academic reference is Guyon and Elisseeff (2003).
4.4.1 Feature selection¶
The first step is selection. Given a large set of predictors, it seems a sound idea to filter out unwanted or redundant exogenous variables. Heuristically, simple methods include:
- computing the correlation matrix of all features and making sure that no (absolute) value is above a threshold (0.7 is a common value) so that redundant variables do not pollute the learning engine;
- carrying out a linear regression and removing the non significant variables (e.g., those with p-value above 0.05).
- perform a clustering analysis over the set of features and retain only one feature within each cluster (see Chapter 15).
Both these methods are somewhat reductive and overlook nonlinear relationships. Another approach would be to fit a decision tree (or a random forest) and retain only the features that have a high variable importance. These methods will be developed in Chapter 6 for trees and Chapter 13 for variable importance.
4.4.2 Scaling the predictors¶
The premise of the need to pre-process the data comes from the large variety of scales in financial data:
- returns are most of the time smaller than one in absolute value;
- stock volatility lies usually between 5% and 80%;
- market capitalization is expressed in million or billion units of a particular currency;
- accounting values as well;
- accounting ratios can have inhomogeneous units;
- synthetic attributes like sentiment also have their idiosyncrasies.
While it is widely considered that monotonic transformations of the features have a marginal impact on prediction outcomes, Galili and Meilijson (2016) show that this is not always the case (see also Section 4.8.2). Hence, the choice of normalization may in fact very well matter.
If we write xi for the raw input and ~xi for the transformed data, common scaling practices include:
- standardization: $\tilde{x}_i=(x_i-m_x)/\sigma_x$, where mx and σx are the mean and standard deviation of x, respectively;
- min-max rescaling over [0,1]:$\tilde{x}_i=(x_i-\min(\mathbf{x}))/(\max(\mathbf{x})-\min(\mathbf{x}))$
- min-max rescaling over [-1,1]:$\tilde{x}_i=2\frac{x_i-\min(\mathbf{x})}{\max(\mathbf{x})-\min(\mathbf{x})}-1$
- uniformization: $\tilde{x}_i=F_\mathbf{x}(x_i)$ where Fx is the empirical c.d.f. of x. In this case, the vector ~x is defined to follow a uniform distribution over [0,1].
Sometimes, it is possible to apply a logarithmic transform of variables with both large values (market capitalization) and large outliers. The scaling can come after this transformation. Obviously, this technique is prohibited for features with negative values.
It is often advised to scale inputs so that they range in [0,1] before sending them through the training of neural networks for instance. The dataset that we use in this book is based on variables that have been uniformized: for each point in time, the cross-sectional distribution of each feature is uniform over the unit interval. In factor investing, the scaling of features must be operated separately for each date and each feature. This point is critical. It makes sure that for every rebalancing date, the predictors will have a similar shape and do carry information on the cross-section of stocks.
Uniformization is sometimes presented differently: for a given characteristic and time, characteristic values are ranked and the rank is then divided by the number of non-missing points. This is done in Freyberger, Neuhierl, and Weber (2020) for example. In Kelly, Pruitt, and Su (2019), the authors perform this operation but then subtract 0.5 to all features so that their values lie in [-0.5,0.5].
Scaling features across dates should be proscribed. Take for example the case of market capitalization. In the long run (market crashes notwithstanding), this feature increases through time. Thus, scaling across dates would lead to small values at the beginning of the sample and large values at the end of the sample. This would completely alter and dilute the cross-sectional content of the features.
4.5 Labelling¶
4.5.1 Simple labels¶
There are several ways to define labels when constructing portfolio policies. Of course, the finality is the portfolio weight, but it is rarely considered as the best choice for the label.10
Usual labels in factor investing are the following:
- raw asset returns;
- future relative returns (versus some benchmark: market-wide index, or sector-based portfolio for instance). One simple choice is to take returns minus a cross-sectional mean or median;
- the probability of positive return (or of return above a specified threshold);
- the probability of outperforming a benchmark (computed over a given time frame);
- the binary version of the above: YES (outperforming) versus NO (underperforming);
- risk-adjusted versions of the above: Sharpe ratios, information ratios, MAR or CALMAR ratios (see Section 12.3).
When creating binary variables, it is often tempting to create a test that compares returns to zero (profitable versus non profitable). This is not optimal because it is very much time-dependent. In good times, many assets will have positive returns, while in market crashes, few will experience positive returns, thereby creating very unbalanced classes. It is a better idea to split the returns in two by comparing them to their time-$t$ median (or average). In this case, the indicator is relative and the two classes are much more balanced.
As we will discuss later in this chapter, these choices still leave room for additional degrees of freedom. Should the labels be rescaled, just like features are processed? What is the best time horizon on which to compute performance metrics?
4.5.2 Categorical labels¶
In a typical ML analysis, when $y$ is a proxy for future performance, the ML engine will try to minimize some distance between the predicted value and the realized values. For mathematical convenience, the sum of squared error ($L^2$ norm) is used because it has the simplest derivative and makes gradient descent accessible and easy to compute.
Sometimes, it can be interesting not to focus on raw performance proxies, like returns or Sharpe ratios, but on discrete investment decisions, which can be derived from these proxies. A simple example (decision rule) is the following:
where $\hat{r}_{t,i}$ is the performance proxy (e.g., returns or Sharpe ratio) and $r_\pm$ are the decision thresholds. When the predicted performance is below $r−$, the decision is -1 (e.g., sell), when it is above $r_+$, the decision is +1 (e.g., buy) and when it is in the middle (the model is neither very optimistic nor very pessimistic), then the decision is neutral (e.g., hold). The performance proxy can of course be relative to some benchmark so that the decision is directly related to this benchmark. It is often advised that the thresholds $r_\pm$ be chosen such that the three categories are relatively balanced, that is, so that they end up having a comparable number of instances.
In this case, the final output can be considered as categorical or numerical because it belongs to an important subgroup of categorical variables: the ordered categorical (ordinal) variables. If $y$ is taken as a number, the usual regression tools apply.
When $y$ is treated as a non-ordered (nominal) categorical variable, then a new layer of processing is required because ML tools only work with numbers. Hence, the categories must be recoded into digits. The mapping that is most often used is called ‘one-hot encoding’. The vector of classes is split in a sparse matrix in which each column is dedicated to one class. The matrix is filled with zeros and ones. A one is allocated to the column corresponding to the class of the instance. We provide a simple illustration in the table below.
TABLE 4.2: Concise example of one-hot encoding.
| Initial data | One-hot | encoding | ||
|---|---|---|---|---|
| Position | Sell | Buy | Buy | |
| buy | 0 | 0 | 1 | |
| buy | 0 | 0 | 1 | |
| hold | 0 | 1 | 0 | |
| sell | 1 | 0 | 0 | |
| buy | 0 | 0 | 1 |
In classification tasks, the output has a larger dimension. For each instance, it gives the probability of belonging to each class assigned by the model. As we will see in Chapters 6 and 7, this is easily handled via the softmax function.
From the standpoint of allocation, handling categorical predictions is not necessarily easy. For long-short portfolios, plus or minus one signals can provide the sign of the position. For long-only portfolio, two possible solutions: (i) work with binary classes (in versus out of the portfolio) or (ii) adapt weights according to the prediction: zero weight for a -1 prediction, 0.5 weight for a 0 prediction and full weight for a +1 prediction. Weights are then of course normalized so as to comply with the budget constraint.
4.5.3 The triple barrier method¶
We conclude this section with an advanced labelling technique mentioned in De Prado (2018). The idea is to consider the full dynamics of a trading strategy and not a simple performance proxy. The rationale for this extension is that often money managers implement P&L triggers that cash in when gains are sufficient or opt out to stop their losses. Upon inception of the strategy, three barriers are fixed (see Figure 4.4):
- one above the current level of the asset (magenta line), which measures a reasonable expected profit;
- one below the current level of the asset (cyan line), which acts as a stop-loss signal to prevent large negative returns;
- and finally, one that fixes the horizon of the strategy after which it will be terminated (black line).
If the strategy hits the first (resp. second) barrier, the output is +1 (resp. -1), and if it hits the last barrier, the output is equal to zero or to some linear interpolation (between -1 and +1) that represents the position of the terminal value relative to the two horizontal barriers. Computationally, this method is much more demanding, as it evaluates a whole trajectory for each instance. Again, it is nonetheless considered as more realistic because trading strategies are often accompanied with automatic triggers such as stop-loss, etc.
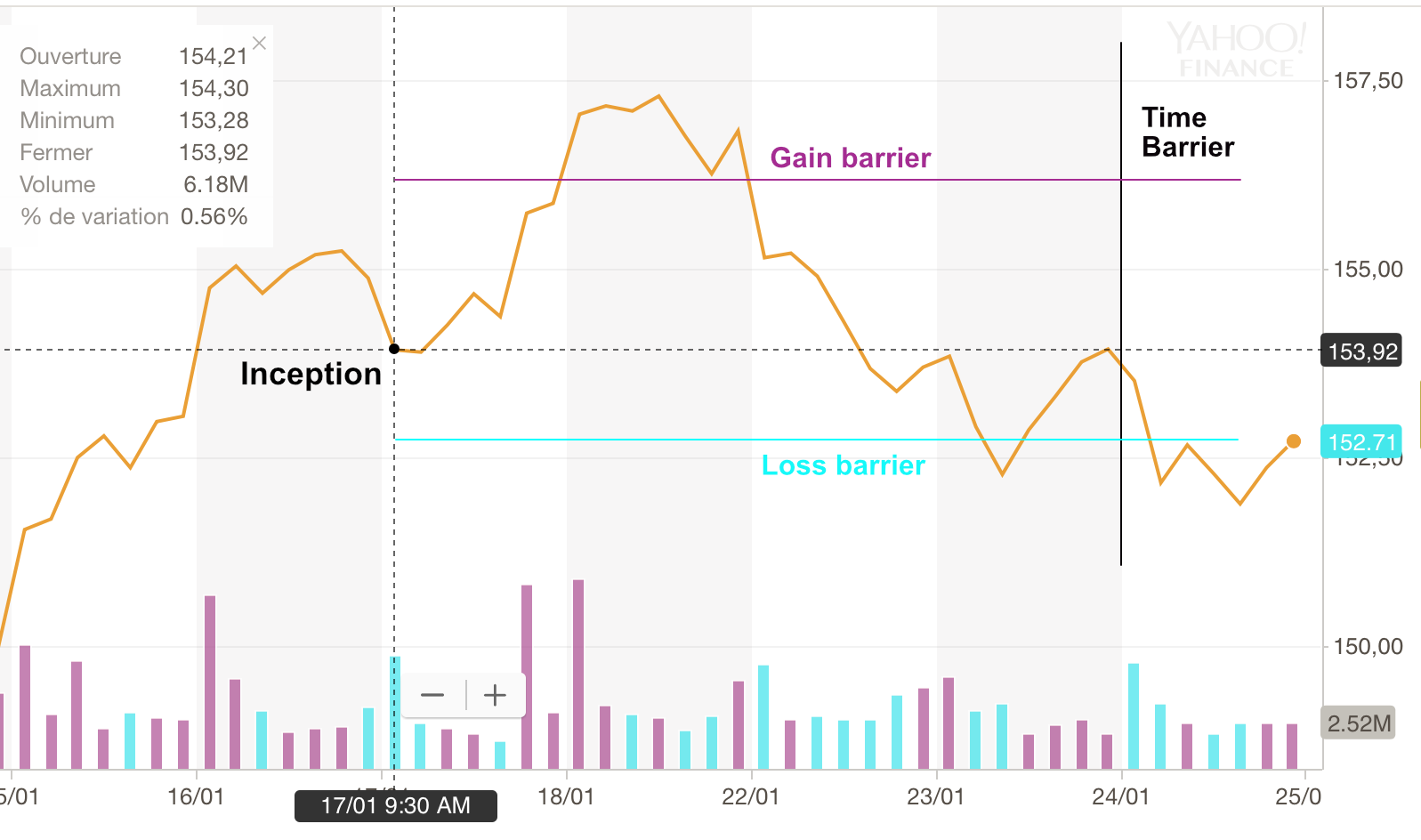
FIGURE 4.4: Illustration of the triple barrier method.
4.5.4 Filtering the sample¶
One of the main challenges in Machine Learning is to extract as much signal as possible. By signal, we mean patterns that will hold out-of-sample. Intuitively, it may seem reasonable to think that the more data we gather, the more signal we can extract. This is in fact false in all generality because more data also means more noise. Surprisingly, filtering the training samples can improve performance. This idea was for example implemented successfully in Fu et al. (2018), Guida and Coqueret (2018a) and Guida and Coqueret (2018b).
In Coqueret and Guida (2020), we investigate why smaller samples may lead to superior out-of-sample accuracy for a particular type of ML algorithm: decision trees (see Chapter 6). We focus on a particular kind of filter: we exclude the labels (e.g., returns) that are not extreme and retain the 20% values that are the smallest and the 20% that are the largest (the bulk of the distribution is removed). In doing so, we alter the structure of trees in two ways:
- when the splitting points are altered, they are always closer to the center of the distribution of the splitting variable (i.e., the resulting clusters are more balanced and possibly more robust);
- the choice of splitting variables is (sometimes) pushed towards the features that have a monotonic impact on the label.
These two properties are desirable. The first reduces the risk of fitting to small groups of instances that may be spurious. The second gives more importance to features that appear globally more relevant in explaining the returns. However, the filtering must not be too intense. If, instead of retaining 20% of each tail of the predictor, we keep just 10%, then the loss in signal becomes too severe and the performance deteriorates.
4.5.5 Return horizons¶
This subsection deals with one of the least debated issues in factor-based machine learning models: horizons. Several horizons come into play during the whole ML-driven allocation workflow: the horizon of the label, the estimation window (chronological depth of the training samples) and the holding periods. One early reference that looks at these aspects is the founding academic paper on momentum by Jegadeesh and Titman (1993). The authors compute the profitability of portfolios based on the returns over the past $J=3, 6, 9, 12$ months. Four holding periods are tested: $K=3,6,9,12$ months. They report: “The most successful zero-cost (long-short) strategy selects stocks based on their returns over the previous 12 months and then holds the portfolio for 3 months.” While there is no machine learning whatsoever in this contribution, it is possible that their conclusion that horizons matter may also hold for more sophisticated methods. This topic is in fact much discussed, as is shown by the continuing debate on the impact of horizons in momentum profitability (see, e.g., Novy-Marx (2012), Gong, Liu, and Liu (2015) and Goyal and Wahal (2015)).
This debate should also be considered when working with ML algorithms. The issues of estimation windows and holding periods are mentioned later in the book, in Chapter 12. Naturally, in the present chapter, the horizon of the label is the important ingredient. Heuristically, there are four possible combinations if we consider only one feature for simplicity:
- oscillating label and feature;
- oscillating label, smooth feature (highly autocorrelated);
- smooth label, oscillating feature;
- smooth label and feature.
Of all of these options, the last one is probably preferable because it is more robust, all things being equal.11 By all things being equal, we mean that in each case, a model is capable of extracting some relevant pattern. A pattern that holds between two slowly moving series is more likely to persist in time. Thus, since features are often highly autocorrelated (cf Figure 4.3), combining them with smooth labels is probably a good idea. To illustrate how critical this point is, we will purposefully use 1-month returns in most of the examples of the book and show that the corresponding results are often disappointing. These returns are very weakly autocorrelated while 6-month or 12-month returns are much more persistent and are better choices for labels.
Theoretically, it is possible to understand why that may be the case. For simplicity, let us assume a single feature $x$ that explains returns $r_{t+1}=f(x_t)+e_{t+1}$. If $xt$ is highly autocorrelated and the noise embeded in $e_{t+1}$ is not too large, then the two-period ahead return $(1+r_{t+1})(1+r_{t+2})-1$ may carry more signal than $r_{t+1}$ because the relationship with $x_t$ has diffused and compounded through time. Consequently, it may also be beneficial to embed memory considerations directly into the modelling function, as is done for instance in Matthew F Dixon (2020). We discuss some practicalities related to autocorrelations in the next section.
4.6 Handling persistence¶
While we have separated the steps of feature engineering and labelling in two different subsections, it is probably wiser to consider them jointly. One important property of the dataset processed by the ML algorithm should be the consistency of persistence between features and labels. Intuitively, the autocorrelation patterns between the label $y_{t,n}$ (future performance) and the features $x_{t,n}^{(k)}$ should not be too distant.
One problematic example is when the dataset is sampled at the monthly frequency (not unusual in the money management industry) with the labels being monthly returns and the features being risk-based or fundamental attributes. In this case, the label is very weakly autocorrelated, while the features are often highly autocorrelated. In this situation, most sophisticated forecasting tools will arbitrage between features which will probably result in a lot of noise. In linear predictive models, this configuration is known to generate bias in estimates (see the study of Stambaugh (1999) and the review by Gonzalo and Pitarakis (2018)).
Among other more technical options, there are two simple solutions when facing this issue: either introduce autocorrelation into the label, or remove it from the features. Again, the first option is not advised for statistical inference on linear models. Both are rather easy econometrically:
- to increase the autocorrelation of the label, compute performance over longer time ranges. For instance, when working with monthly data, considering annual or biennial returns will do the trick.
- to get rid of autocorrelation, the shortest route is to resort to differences/variations:$\Delta x_{t,n}^{(k)}=x_{t,n}^{(k)}-x_{t-1,n}^{(k)}$. One advantage of this procedure is that it makes sense, economically: variations in features may be better drivers of performance, compared to raw levels.
A mix between persistent and oscillating variables in the feature space is of course possible, as long as it is driven by economic motivations.
4.7 Extensions¶
4.7.1¶
The feature space can easily be augmented through simple operations. One of them is lagging, that is, considering older values of features and assuming some memory effect for their impact on the label. This is naturally useful mostly if the features are oscillating (adding a layer of memory on persistent features can be somewhat redundant). New variables are defined by $\breve{x}_{t,n}^{(k)}=x_{t-1,n}^{(k)}$
In some cases (e.g., insufficient number of features), it is possible to consider ratios or products between features. Accounting ratios like price-to-book, book-to-market, debt-to-equity are examples of functions of raw features that make sense. The gains brought by a larger spectrum of features are not obvious. The risk of overfitting increases, just like in a simple linear regression adding variables mechanically increases the $R^2$. The choices must make sense, economically.
Another way to increase the feature space (mentioned above) is to consider variations. Variations in sentiment, variations in book-to-market ratio, etc., can be relevant predictors because sometimes, the change is more important than the level. In this case, a new predictor is $\breve{x}_{t,n}^{(k)}=x_{t,n}^{(k)}-x_{t-1,n}^{(k)}$
4.7.2 Macro-economic variables¶
Finally, we discuss a very important topic. The data should never be separated from the context it comes from (its environment). In classical financial terms, this means that a particular model is likely to depend on the overarching situation which is often proxied by macro-economic indicators. One way to take this into account at the data level is simply to multiply the feature by an exogenous indicator $z_{t}$ and in this case, the new predictor is
This technique is used by Gu, Kelly, and Xiu (2020b) who use 8 economic indicators (plus the original predictors $(z_t=1))$. This increases the feature space ninefold.
Another route that integrates shifting economic environments is conditional engineering. Suppose that labels are coded via formula (4.2). The thresholds can be made dependent on some exogenous variable. In times of turbulence, it might be a good idea to increase both $r_+$ (buy threshold) and $r_-$ (sell threshold) so that the labels become more conservative: it takes a higher return to make it to the buy category, while short positions are favored. One such example of dynamic thresholding could be
where $\text{VIX}_t$ is the time-$t$ value of the VIX, while $\bar{\text{VIX}}$ is some average or median value. When the VIX is above its average and risk seems to be increasing, the thresholds also increase. The parameter $\delta$ tunes the magnitude of the correction. In the above example, we assume $r_-<0<r_+$.
4.7.3 Active learning¶
We end this section with the notion of active learning. To the best of our knowledge, it is not widely used in quantitative investment, but the underlying concept is enlightening, hence we dedicate a few paragraphs to this notion for the sake of completeness.
In general supervised learning, there is sometimes an asymmetry in the ability to gather features versus labels. For instance, it is free to have access to images, but the labelling of the content of the image (e.g., “a dog”, “a truck”, “a pizza”, etc.) is costly because it requires human annotation. In formal terms, $\textbf{X}$ is cheap but the corresponding $\textbf{y}$ is expensive.
As is often the case when facing cost constraints, an evident solution is greed. Ahead of the usual learning process, a filter (often called query) is used to decide which data to label and train on (possibly in relationship with the ML algorithm). The labelling is performed by a so-called oracle (which/who knows the truth), usually human. This technique that focuses on the most informative instances is referred to as active learning. We refer to the surveys of Settles (2009) and Settles (2012) for a detailed account of this field (which we briefly summarize below). The term active comes from the fact that the learner does not passively accept data samples but actively participates in the choices of items it learns from.
One major dichotomy in active learning pertains to the data source $\textbf{X}$ on which the query is based. One obvious case is when the original sample $\textbf{X}$ is very large and not labelled and the learner asks for particular instances within this sample to be labelled. The second case is when the learner has the ability to simulate/generate its own values $\textbf{x}_i$. This can sometimes be problematic if the oracle does not recognize the data that is generated by the machine. For instance, if the purpose is to label images of characters and numbers, the learner may generate shapes that do not correspond to any letter or digit: the oracle cannot label it.
In active learning, one key question is, how does the learner choose the instances to be labelled? Heuristically, the answer is by picking those observations that maximize learning efficiency. In binary classification, a simple criterion is the probability of belonging to one particular class. If this probability is far from 0.5, then the algorithm will have no difficulty of picking one class (even though it can be wrong). The interesting case is when the probability is close to 0.5: the machine may hesitate for this particular instance. Thus, having the oracle label it is useful in this case because it helps the learner in a configuration in which it is undecided.
Other methods seek to estimate the fit that can be obtained when including particular (new) instances in the training set, and then to optimize this fit. Recalling Section 3.1 in Geman, Bienenstock, and Doursat (1992) on the variance-bias tradeoff, we have, for a training dataset $D$ and one instance $x$ (we omit the bold font for simplicity),
$\mathbb{E}\left[\left.(y-\hat{f}(x;D))^2\right|\{D,x\}\right]=\mathbb{E}\left[\left.\underbrace{(y-\mathbb{E}[y|x])^2}_{\text{indep. from }D\text{ and }\hat{f}} \right|\{D,x\} \right]+(\hat{f}(x;D)-\mathbb{E}[y|x])^2,$
where the notation $f(x;D)$ is used to highlight the dependence between the model $\hat{f}$ and the dataset $D$
: the model has been trained on
D
. The first term is irreducible, as it does not depend on
^
f
. Thus, only the second term is of interest. If we take the average of this quantity, taken over all possible values of
D
:
$\mathbb{E}_D\left[(\hat{f}(x;D)-\mathbb{E}[y|x])^2 \right]=\underbrace{\left(\mathbb{E}_D\left[\hat{f}(x;D)-\mathbb{E}[y|x]\right]\right)^2}_{\text{squared bias}} \ + \ \underbrace{\mathbb{E}_D\left[(\hat{f}(x,D)-\mathbb{E}_D[\hat{f}(x;D)])^2\right]}_{\text{variance}}$
If this expression is not too complicated to compute, the learner can query the $x$ that minimizes the tradeoff. Thus, on average, this new instance will be the one that yields the best learning angle (as measured by the $L2$ error). Beyond this approach (which is limited because it requires the oracle to label a possibly irrelevant instance), many other criteria exist for querying and we refer to section 3 from Settles (2009) for an exhaustive list.
One final question: is active learning applicable to factor investing? One straightfoward answer is that data cannot be annotated by human intervention. Thus, the learners cannot simulate their own instances and ask for corresponding labels. One possible option is to provide the learner with $\textbf{X}$ but not $\textbf{y}$ and keep only a queried subset of observations with the corresponding labels. In spirit, this is close to what is done in Coqueret and Guida (2020) except that the query is not performed by a machine but by the human user. Indeed, it is shown in this paper that not all observations carry the same amount of signal. Instances with ‘average’ label values seem to be on average less informative compared to those with extreme label values.
4.8 Additional code and results¶
4.8.1 Impact of rescaling: graphical representation¶
We start with a simple illustration of the different scaling methods. We generate an arbitrary series and then rescale it. The series is not random so that each time the code chunk is executed, the output remains the same.
length = 100
x = np.exp(np.sin(np.linspace(1,length,length)))
data = pd.DataFrame(data=x,columns=['X'])
data.reset_index(inplace=True)
plt.figure(figsize=(13,5)) # resizing figure
sns.barplot(y="X", data=data, x="index", color='black'); # Plot from Seaborn
plt.xticks(data['index'][::10]); # reshape the xtick every 10 observations

We define and plot the scaled variables below.
from statsmodels.distributions.empirical_distribution import ECDF # to use the ECDF built in function
def norm_0_1(x):
return (x-np.min(x))/(np.max(x)-np.min(x))
def norm_unif(x):
return (ECDF(x)(x))
def norm_standard(x):
return (x- np.mean(x))/np.std(x)
data_norm=pd.DataFrame.from_dict(dict( # ensembling numpy arrays into a dict and then a pd dataframe
index=np.linspace(1,length,length), # creating the index
norm_0_1=norm_0_1(x), # normalisation [0,1]
norm_standard=norm_standard(x), # standardisation
norm_unif=norm_unif(x))) # Uniformisation
data_norm.iloc[:,1:4].plot.bar( figsize=(14,10), subplots=True, sharey=True, sharex=True); # Plot
plt.xticks(data['index'][::10]); # reshape the xtick every 10 observations

Finally, we look at the histogram of the newly created variables.
data_norm.iloc[:,1:4].plot.hist(alpha=0.5, bins=30, figsize=(14,5)); # Plot from pandas, alphas=opacity

With respect to shape, the blue and orange distributions are close to the original one. It is only the support that changes: the min/max rescaling ensures all values lie in the $[0,1]$ interval. In both cases, the smallest values (on the left) display a spike in distribution. By construction, this spike disappears under the uniformization: the points are evenly distributed over the unit interval.
4.8.2 Impact of rescaling: toy example¶
To illustrate the impact of choosing one particular rescaling method,$^{13}$ we build a simple dataset, comprising 3 firms and 3 dates.
import statsmodels.api as sm
from IPython.display import display, Markdown
cap=np.array([10,50,100, # Market capitalization
15,10,15,
200,120,80])
returns=np.array([0.06,0.01,-0.06, # Return values
-0.03,0.00,0.02,
-0.04,-0.02,0.00])
date=np.array([1,2,3,1,2,3,1,2,3]) # Dates
firm=np.array([1,1,1,2,2,2,3,3,3]) # Firms (3 lines for each)
toy_data=pd.DataFrame.from_dict(dict(firm=firm,date=date,cap=cap,returns=returns, # Aggregation of data
cap_norm=norm_0_1(cap),
cap_u=norm_unif(cap)))
display(Markdown(toy_data.to_markdown())) # Introducing Markdown and printing the table
TABLE 4.3: Sample data for a toy example.
Let’s briefly comment on this synthetic data. We assume that dates are ordered chronologically and far away: each date stands for a year or the beginning of a decade, but the (forward) returns are computed on a monthly basis. The first firm is hugely successful and multiplies its cap ten times over the periods. The second firm remains stable cap-wise, while the third one plummets. If we look at ‘local’ future returns, they are strongly negatively related to size for the first and third firms. For the second one, there is no clear pattern.
Date-by-date, the analysis is fairly similar, though slightly nuanced.
- On date 1, the smallest firm has the largest return and the two others have negative returns.
- On date 2, the biggest firm has a negative return while the two smaller firms do not.
- On date 3, returns are decreasing with size. While the relationship is not always perfectly monotonous, there seems to be a link between size and return and, typically, investing in the smallest firm would be a very good strategy with this sample.
Now let us look at the output of simple regressions.
X=toy_data.cap_norm.to_numpy()
X=sm.add_constant(X)
model = sm.OLS(returns, X)
results = model.fit()
print(results.summary())
TABLE 4.4: Regression output when the independent var. comes from min-max rescaling
X=toy_data.cap_u.to_numpy()
X=sm.add_constant(X)
model = sm.OLS(returns, X)
results = model.fit()
print(results.summary())
TABLE 4.5: Regression output when the indep. var. comes from uniformization
In terms of p-value (column P>|t|), the first estimation for the cap coefficient is above 5% (in Table 4.4) while the second is below 5% (in Table 4.5). One possible explanation for this discrepancy is the standard deviation of the variables. The deviations are equal to 0.34 and 0.27 for cap_norm and cap_u, respectively. Values like market capitalizations can have very large ranges and are thus subject to substantial deviations (even after scaling). Working with uniformized variables reduces dispersion and can help solve this problem.
Note that this is a double-edged sword: while it can help avoid false negatives, it can also lead to false positives.
4.9 Coding exercices¶
- The Federal Reserve of Saint Louis (https://fred.stlouisfed.org) hosts thousands of time series of economic indicators that can serve as conditioning variables. Pick one and apply formula (4.3) to expand the number of predictors. If need be, use the function defined above.
- Create a new categorical label based on formulae (4.4) and (4.2). The time series of the VIX can also be retrieved from the Federal Reserve’s website: https://fred.stlouisfed.org/series/VIXCLS.
- Plot the histogram of the R12M_Usd variable. Clearly, some outliers are present. Identify the stock with highest value for this variable and determine if the value can be correct or not.
References¶
Aggarwal, Charu C. 2013. Outlier Analysis. Springer.
Allison, Paul D. 2001. Missing Data. Vol. 136. Sage publications.
Boehmke, Brad, and Brandon Greenwell. 2019. Hands-on Machine Learning with R. Chapman & Hall / CRC.
Chandola, Varun, Arindam Banerjee, and Vipin Kumar. 2009. “Anomaly Detection: A Survey.” ACM Computing Surveys (CSUR) 41 (3): 15.
Che, Zhengping, Sanjay Purushotham, Kyunghyun Cho, David Sontag, and Yan Liu. 2018. “Recurrent Neural Networks for Multivariate Time Series with Missing Values.” Scientific Reports 8 (1): 6085.
Chen, Long, Zhi Da, and Richard Priestley. 2012. “Dividend Smoothing and Predictability.” Management Science 58 (10): 1834–53.
Coqueret, Guillaume, and Tony Guida. 2020. “Training Trees on Tails with Applications to Portfolio Choice.” Annals of Operations Research 288: 181–221.
De Prado, Marcos Lopez. 2018. Advances in Financial Machine Learning. John Wiley & Sons.
Dixon, Matthew F. 2020. “Industrial Forecasting with Exponentially Smoothed Recurrent Neural Networks.” SSRN Working Paper, no. 3572181.
Enders, Craig K. 2001. “A Primer on Maximum Likelihood Algorithms Available for Use with Missing Data.” Structural Equation Modeling 8 (1): 128–41.
Enders, Craig K. 2010. Applied Missing Data Analysis. Guilford Press.
Freyberger, Joachim, Andreas Neuhierl, and Michael Weber. 2020. “Dissecting Characteristics Nonparametrically.” Review of Financial Studies 33 (5): 2326–77.
Fu, XingYu, JinHong Du, YiFeng Guo, MingWen Liu, Tao Dong, and XiuWen Duan. 2018. “A Machine Learning Framework for Stock Selection.” arXiv Preprint, no. 1806.01743.
Galili, Tal, and Isaac Meilijson. 2016. “Splitting Matters: How Monotone Transformation of Predictor Variables May Improve the Predictions of Decision Tree Models.” arXiv Preprint, no. 1611.04561.
Garcı́a-Laencina, Pedro J, José-Luis Sancho-Gómez, Anı́bal R Figueiras-Vidal, and Michel Verleysen. 2009. “K Nearest Neighbours with Mutual Information for Simultaneous Classification and Missing Data Imputation.” Neurocomputing 72 (7-9): 1483–93.
Geman, Stuart, Elie Bienenstock, and René Doursat. 1992. “Neural Networks and the Bias/Variance Dilemma.” Neural Computation 4 (1): 1–58.
Gong, Qiang, Ming Liu, and Qianqiu Liu. 2015. “Momentum Is Really Short-Term Momentum.” Journal of Banking & Finance 50: 169–82.
Gonzalo, Jesús, and Jean-Yves Pitarakis. 2018. “Predictive Regressions.” In Oxford Research Encyclopedia of Economics and Finance.
Goyal, Amit, and Sunil Wahal. 2015. “Is Momentum an Echo?” Journal of Financial and Quantitative Analysis 50 (6): 1237–67.
Gu, Shihao, Bryan T Kelly, and Dacheng Xiu. 2020b. “Empirical Asset Pricing via Machine Learning.” Review of Financial Studies 33 (5): 2223–73.
Guida, Tony, and Guillaume Coqueret. 2018a. “Ensemble Learning Applied to Quant Equity: Gradient Boosting in a Multifactor Framework.” In Big Data and Machine Learning in Quantitative Investment, 129–48. Wiley.
Guida, Tony, and Guillaume Coqueret. 2018b. “Machine Learning in Systematic Equity Allocation: A Model Comparison.” Wilmott 2018 (98): 24–33.
Gupta, Manish, Jing Gao, Charu Aggarwal, and Jiawei Han. 2014. “Outlier Detection for Temporal Data.” IEEE Transactions on Knowledge and Data Engineering 26 (9): 2250–67.
Guyon, Isabelle, and André Elisseeff. 2003. “An Introduction to Variable and Feature Selection.” Journal of Lachine Learning Research 3 (Mar): 1157–82.
Hastie, Trevor, Robert Tibshirani, and Jerome Friedman. 2009. The Elements of Statistical Learning. Springer.
Hodge, Victoria, and Jim Austin. 2004. “A Survey of Outlier Detection Methodologies.” Artificial Intelligence Review 22 (2): 85–126.
Honaker, James, and Gary King. 2010. “What to Do About Missing Values in Time-Series Cross-Section Data.” American Journal of Political Science 54 (2): 561–81.
Jegadeesh, Narasimhan, and Sheridan Titman. 1993. “Returns to Buying Winners and Selling Losers: Implications for Stock Market Efficiency.” Journal of Finance 48 (1): 65–91.
Kelly, Bryan T, Seth Pruitt, and Yinan Su. 2019. “Characteristics Are Covariances: A Unified Model of Risk and Return.” Journal of Financial Economics 134 (3): 501–24.
Kuhn, Max, and Kjell Johnson. 2019. Feature Engineering and Selection: A Practical Approach for Predictive Models. CRC Press.
Leary, Mark T, and Roni Michaely. 2011. “Determinants of Dividend Smoothing: Empirical Evidence.” Review of Financial Studies 24 (10): 3197–3249.
Little, Roderick JA, and Donald B Rubin. 2014. Statistical Analysis with Missing Data. Vol. 333. John Wiley & Sons.
Novy-Marx, Robert. 2012. “Is Momentum Really Momentum?” Journal of Financial Economics 103 (3): 429–53.
Rousseeuw, Peter J, and Annick M Leroy. 2005. Robust Regression and Outlier Detection. Vol. 589. Wiley.
Schafer, Joseph L. 1999. “Multiple Imputation: A Primer.” Statistical Methods in Medical Research 8 (1): 3–15.
Settles, Burr. 2009. “Active Learning Literature Survey.” University of Wisconsin-Madison Department of Computer Sciences.
Settles, Burr. 2012. “Active Learning.” Synthesis Lectures on Artificial Intelligence and Machine Learning 6 (1): 1–114.
Shah, Anoop D, Jonathan W Bartlett, James Carpenter, Owen Nicholas, and Harry Hemingway. 2014. “Comparison of Random Forest and Parametric Imputation Models for Imputing Missing Data Using Mice: A Caliber Study.” American Journal of Epidemiology 179 (6): 764–74.
Stambaugh, Robert F. 1999. “Predictive Regressions.” Journal of Financial Economics 54 (3): 375–421.
Stekhoven, Daniel J, and Peter Bühlmann. 2011. “MissForest—Non-Parametric Missing Value Imputation for Mixed-Type Data.” Bioinformatics 28 (1): 112–18.
Van Buuren, Stef. 2018. Flexible Imputation of Missing Data. Chapman & Hall / CRC.
footnotes
10 Some methodologies do map firm attributes into final weights, e.g., Brandt, Santa-Clara, and Valkanov (2009) and Ammann, Coqueret, and Schade (2016), but these are outside the scope of the book.↩︎
11 This is of course not the case for inference relying on linear models. Memory generates many problems and complicates the study of estimators. We refer to Hjalmarsson (2011) and Xu (2020) for theoretical and empirical results on this matter.↩︎
12 For a more thorough technical discussion on the impact of feature engineering, we refer to Galili and Meilijson (2016).↩︎